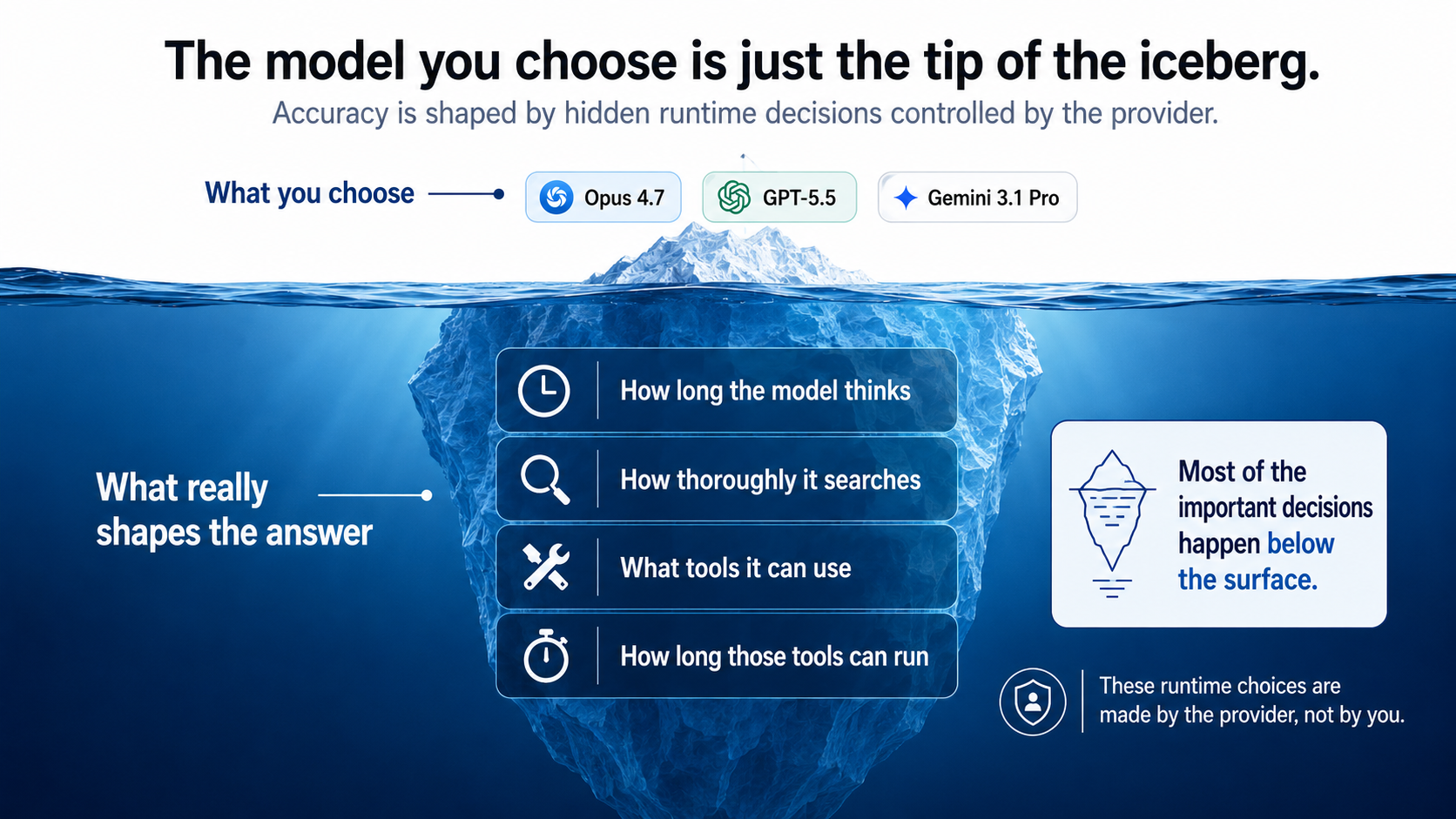
Deep Research you can trust.
VeriLM Deep Research produces a different category of accuracy, depth, and consistency that the other providers can't match.
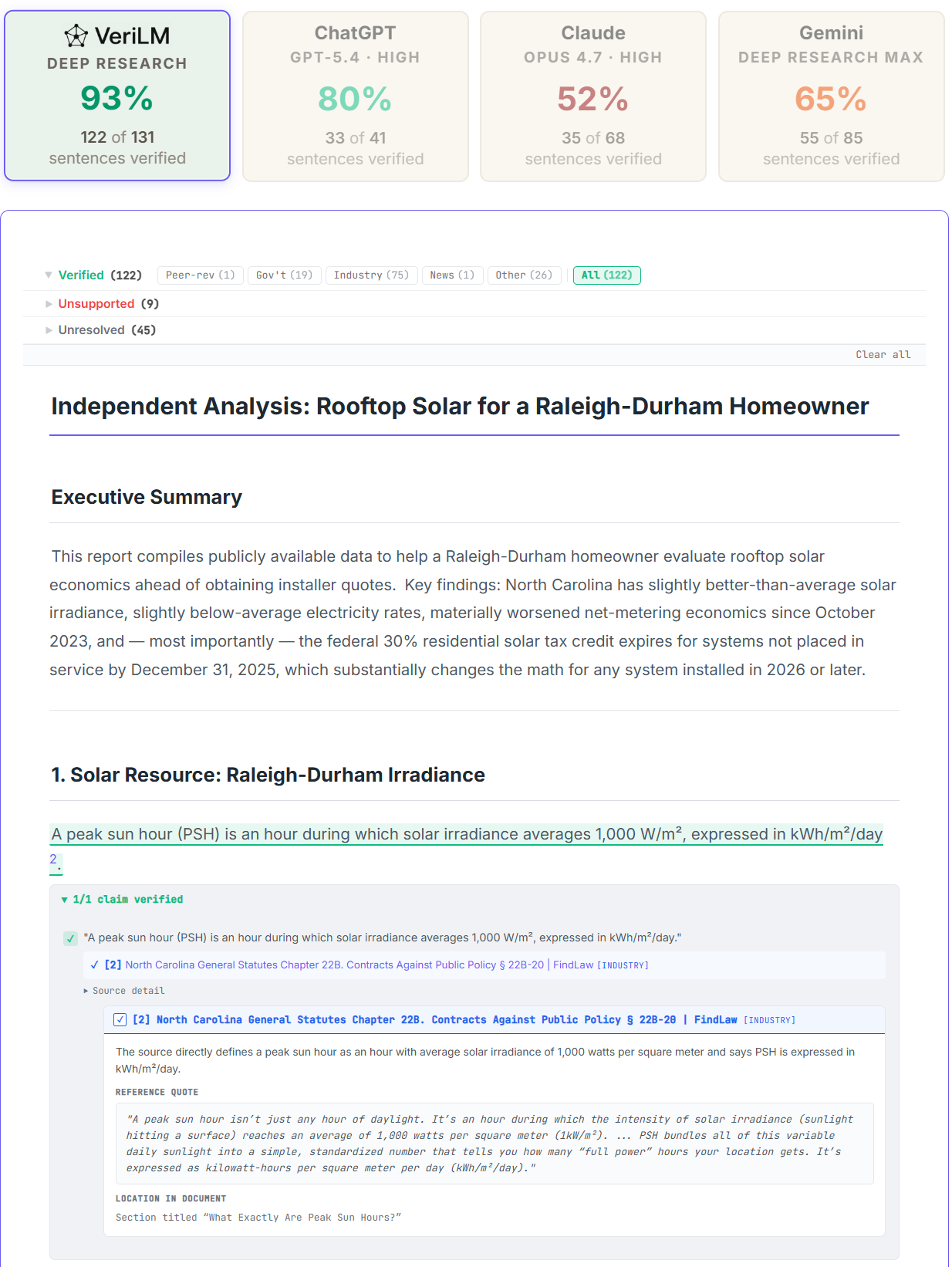
What you're seeing: comparative accuracy across four Deep Research tools (top), and a verified claim with its source detail expanded (below). Click into the live report further down to try it yourself.
Every claim, traceable. Every source, inspectable. Finally, a Deep Research report you can trust: accurate, thorough, consistent, with the embedded grading of every sentence back to the source to prove it.
Here's one example from that test set: the same Raleigh-Durham solar economics question, run through all four tools. Click into any report and use the Verified, Unsupported, and Unresolved dropdowns to see how each claim was scored.