How VeriLM grades.
The point of a Deep Research report is to give you claims you can verify against a source — so you know you aren't reading a hallucination. VeriLM grades every report against that bar, sentence by sentence.
The grading process
Decompose
Every sentence that makes a factual statement is broken into individual claims. This happens whether or not the sentence is cited — uncited claims don't get to skip the grading.
Assign sources
Each sentence with factual claims gets its cited sources attached. A single sentence can pull from multiple sources.
Grade each claim
Every claim is checked against each of its assigned sources individually. If a claim fails against every individual source, a synthesis pass runs — checking the claim against all referenced sources together — before the claim is marked unsupported.
Roll up the verdict
A sentence is verified only if every claim in it is verified. One unsupported claim drags the whole sentence into the unsupported bucket.
The six verdicts
| Verdict | Definition |
|---|---|
| Verified | Every claim in the sentence checks out against at least one of its cited sources. |
| Unsupported — Wrong | A cited source speaks to the claim but contradicts it. Example: the report says "Raleigh gets 213 sunny days per year," but the cited source says 200. |
| Unsupported — Missing | The cited source doesn't speak to the claim at all. |
| Unsupported — Uncited | The sentence makes a factual claim but has no source attached. |
| Unresolved — Unverified | The cited source couldn't be programmatically retrieved, so grading couldn't complete. |
| Unresolved — Narrative | The sentence doesn't make a factual claim. Ungraded by definition. |
The accuracy formula
Unresolved sentences — narrative and unverifiable — are excluded from both numerator and denominator. Narrative doesn't make factual claims, so there's nothing to grade. Unverifiable means the cited source couldn't be retrieved — an operational miss, not a content failure.
By the numbers
Accuracy vs. verified sentences
Across our test set, the providers' results are wildly variable. Anthropic Deep Research ranged from 50% to 97% accuracy across the same 10 questions. Google from 38% to 66%. OpenAI from 61% to 85%. Same prompt, same model — you can't tell from the question which report you'll get.
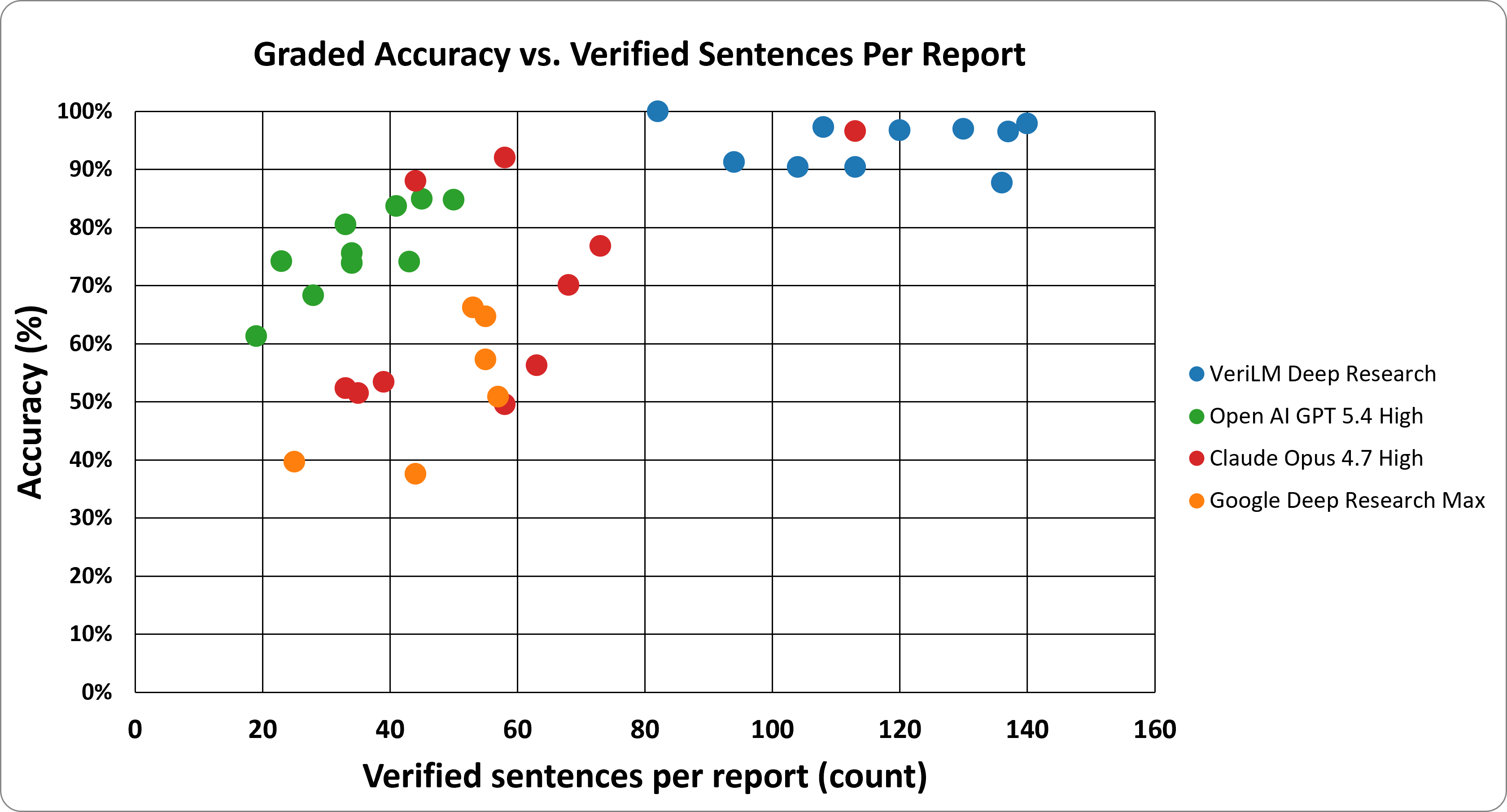
VeriLM Deep Research stays in a tighter band: 88–100% accuracy with 82–140 verified sentences per report. The other providers can hit strong individual reports — Anthropic produced one at 97% — but you can't tell ahead of time which question will land there. VeriLM hits that range reliably.
Unique sources cited
A natural question: does VeriLM hit higher accuracy by surveying narrower? No. The chart below shows unique sources cited per report. VeriLM is in the same neighborhood as Anthropic and Google, and well above OpenAI.
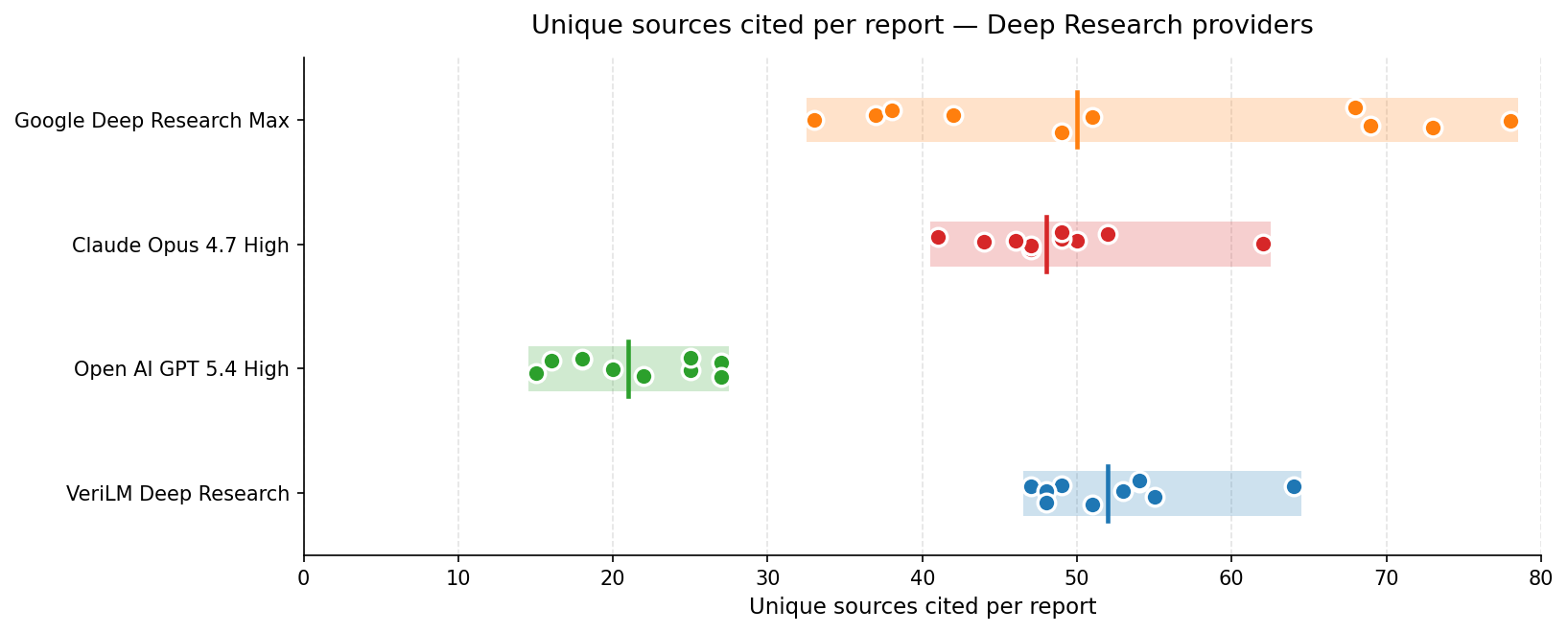
Look at the spreads: Google ranges from 33 to 78 sources per report, Anthropic from 41 to 62, OpenAI from 15 to 27. VeriLM's range is 47–64, with most reports clustered near 50. The point isn't volume; it's that one report looks like the next. Consistency isn't a vanity metric — it's what lets you trust the next report you haven't read yet.
Based on ten reports per provider, May 2026. Each report was independently graded sentence-by-sentence using the process above. Models tested: GPT-5.4 High, Opus 4.7 High, Gemini Deep Research Max.
Want to see VeriLM Deep Research in action? Request beta access below.